
While AI web crawlers redefine how the content is consumed, llms.txt provided the essential control over content consumption to the website owners.
Over the past decade, the digital landscape has transformed: in which once conventional web crawlers indexed pages for search engines like Google, now superior AI bots---especially the ones from large language version (LLM) builders---are collecting website content to teach generative systems. This shift creates fresh possibilities and challenges for website proprietors aiming to manage traffic, shield content, and preserve SEO value. A new tool in this evolving environment is llms.txt, a file layout particularly designed to speak with LLM-centered crawlers. Here's what Cronbay Technologies' team advises every website owner and digital strategist to recognise:
What Are AI Web Crawlers?
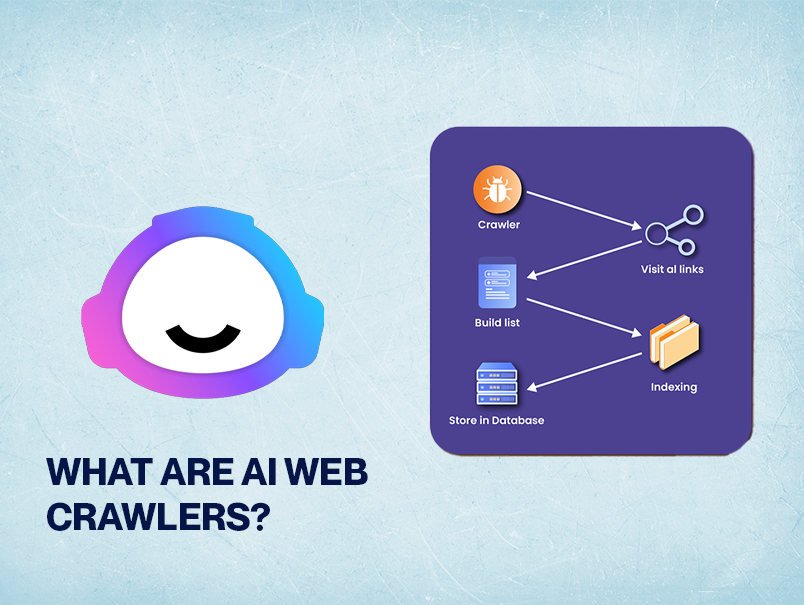
AI web crawlers, also known as machine learning bots, are state-of-the-art programs deployed by using LLM builders like OpenAI, Anthropic, and Google. These crawlers, which includes the nicely‑regarded OpenAI GPTBot, routinely acquire textual data from across the internet. Their purpose: acquire large datasets to train or fine-tune AI‑generated content structures.
These crawlers vary appreciably from conventional search engine crawlers (Googlebot, Bingbot), which index pages for search. AI crawlers often focus on full-content ingestion, and might run a couple of times a day depending on their schooling cycles.
Types of AI Web Crawlers
| Crawler Type | Purpose | Example |
|---|---|---|
| Search Engine Bots | Index and rank web pages | Googlebot, Bingbot |
| LLM Training Bots | Collect content for model training | OpenAI GPTBot |
| Scraping Bots | Harvest specific data (e.g., product pricing) | Custom scrapers |
| Mixed Utility Bots | Combine browsing, ranking, and data series heuristics | Unknown/Proprietary crawlers |
AI web crawlers focus on large language model content sourcing--regularly dismissing robots.txt and metadata supposed for serps, running instead on datasets optimized for AI studying.
What Is llms.txt?

Enter llms.txt---a popular file, mirroring robots.txt in structure, that website proprietors can use to allow or disallow access to AI crawlers. It facilitates control of how AI‑generated content structures have interaction with your area.
A typical llms.txt might look like:
makefile
User-agent: GPTBot
Allow: /
User-agent: LLaMAIndexer
Disallow: /
User-agent: *
Disallow: /
This configuration tells GPTBot it could crawl your site, blocks all access by LLaMAIndexer, and denies others access completely.
Why Is llms.txt Important?
1. Protecting Severe Content
AI crawlers may scrape large volumes of content, consisting of premium articles or proprietary data. Without right rules, your treasured assets hazard extraction for broader AI training.
2. Managing Server Load
AI bots can create hundreds of heavy site visitors. By permitting only reliable retailers, website proprietors can lessen useless strain and preserve performance.
3. SEO Impact and Bot Attribution
Allowing unregulated AI crawling may inflate visitors stats without meaningful user engagement and confuse analytics. Proper specification ensures correct bot segmentation and facts interpretation.
Also Read: Is SEO Really Dead in 2025? Here's the Truth Nobody's Telling You
4. Formalizing Ethical AI Practices
The upward push of moral AI web scraping needs more transparency. Providing llms.txt helps web standards in a way that aligns with AI and website data utilization satisfactory practices.
How to Set Up llms.txt for Your Site
- Create the report llms.txt in your website root directory.
- Identify acknowledged AI bots, like GPTBot, AnthropicBot, and others. If unknown crawlers seem in server logs, keep in mind blocking them.
- Define your regulations, figuring out which crawlers to allow and block selectively.
Test using curl:
url https://yourdomain.com/llms.txt
- Ensure accessibility and proper formatting.
- Stay up to date, monitoring access logs month-to-month to alter policies as new bots appear.
- Combine with robots.txt, ensuring classic search engines and AI platforms abide by means of your pointers.
llms.txt vs robots.txt
- robots.txt: Manages access from serps and traditional bots.
- Llms.txt: Specifically designed to control large language version crawlers.
- AI bots often forget about robots.txt, however they'll check llms.txt to avoid undesirable content harvesting.
Using each ensures complete management---search-indexing through robots.txt, and AI ingestion through llms.txt.
Tips for Optimization
- Use clear naming conventions: Keep llms.txt in root and mention its presence in robots.txt or human-readable pages.
- Adjust regulations strategically: For example, permit crawling of your weblog but block image-heavy sections.
- Whitelist responsibly: Allow only professional crawlers with obvious usage policies.
- Review server logs monthly: Identify new crawlers and alter llms.txt as a consequence.
- Publish a bot coverage on your website: Explain how you deal with bot traffic, fostering belief with both AI companions and users.
How AI-Driven Search Changes Content Visibility
Traditional search engine crawlers determine content for relevance and rating. AI web crawlers, conversely, are looking for in-depth content evaluation to feed into machine studying bots and large language model content sourcing. When those crawlers access content:
- They seize more than indexable tags---often extracting entire articles, product listings, and metadata.
- They save the facts to educate fashions that power AI assistants, chatbots, and autogenerated summaries.
- They affect content visibility throughout third party interfaces like Q&A systems and voice assistants.
This new paradigm requires website crawling techniques to balance discoverability with brand management. For instance, disallowing search engine bots in robots.txt may additionally lessen visibility, at the same time as the use of llms.txt controls whether or not AI crawlers can collect content for version training.
Challenges for Website Owners
Content Scraping through LLMs
AI crawlers---designed for GPTBot, BingAI, or proprietary scrapers---may additionally accumulate content without person interplay. This can dilute brand authority while snippets appear in AI summaries out of doors to your direct manager.
Data Privacy and Misuse
Exposed content might be used improperly, leading to incorrect information, logo dilution, or lack of competitive advantage. Once scraped, content can also proliferate across the web in difficult-to-track ways.
SEO Impact of AI Data Collection
With AI-generated content influencing search consequences, unique publishers may additionally lose SEO attribution. Meanwhile, duplicated content from AI resources can create pagination problems, attribution disputes, or ratings fluctuations.
Pros and Cons of Allowing AI Web Crawlers
Pros
- Amplified Reach: AI-displayed snippets can power indirect traffic.
- SEO Uplift: Some AI summaries reference unique sources transparently.
- Analytics Value: Detecting AI crawler visits helps refine content strategies.
Cons
- Risk of Misuse: Content may be repackaged or diluted.
- Server Overload: A surprising slow spike can hurt performance.
- Ethical Site Use: Data may be utilized in ways you didn't anticipate.
Content Governance: Robots.txt vs llms.txt
robots.txt governs search engine bots, e.g.:
User-agent: *
Disallow: /personal/
These directives help control indexing but don't forestall AI schooling.
Enter llms.txt, a new standard that signals AI web crawlers:
User-agent: GPTBot
Disallow: /
User-agent: *
Disallow:
This instructs LLM-based crawlers no longer to manoeuvre content for training, although it's available to human readers.
Cronbay Technologies recommends web proprietors use both:
- robots.txt for search engine visibility.
- Llms.txt for AI content governance and IP protection.
Who's Using llms.txt?
Leading systems have begun enforcing llms.txt, consisting of:
- OpenAI GPTBot: Abides with the aid of llms.txt to admire non-consensual data series.
- Anthropic: Publicly adopts llms.txt compliance to avoid IP concerns.
- Google Bard and BingAI: Likely to observe in shape as standard adoption grows.
Future of SEO and Content Protection inside the AI Era

The upward thrust of AI-generated content way content authenticity and management are increasingly crucial. As AI summaries and assistants have an impact on user behaviour, search engines will probably refine ranking algorithms to favour confirmed resources. Proper use of llms.txt and dependent metadata will signal content possession and trustworthiness.
Best Practices for Managing AI Bot Access
- Define Bot Access: Clearly permit or restriction access in robots.txt and llms.txt.
- Monitor Bot Traffic: Use server logs to distinguish between search bots and AI crawlers.
- Optimize Crawl Paths: Ensure vital pages stay on hand to search engines like Google while controlling AI bot impact.
- Prioritize Data Privacy: Limit publicity of personal or sensitive records to AI scrapers.
- Keep Documentation Updated: Pair each protocol with updated sitemaps and content inventories.
Conclusion: Embrace AI, Govern Content
The era of AI web crawlers and llms.txt signals a critical shift---they empower website owners to control content access throughout each search and AI systems. Brands should embody AI's ability even as advocating for transparency and attribution.
Cronbay Technologies gives tailored assist in digital marketing, which includes:
- SEO strategy layout
- Mobile-first content audits
- Insight-pushed analytics for AI traffic
Partnering with Cronbay ensures your brand navigates each visibility and safety within the AI age. Connect with our specialists to adopt llms.txt and redefine your website governance.
Also Read:
FAQs
1. What is llms.txt?
Llms.txt is a newly delivered protocol file that lets website owners govern how AI web crawlers, especially the ones used by Large Language Models (LLMs) like GPT and Claude, interact with their website content. Much like the conventional robots.txt, the llms.txt report is placed inside the root directory of a website and indicators to system learning bots whether or not they're allowed to get right of entry to, move slowly, or index precise parts---or all---of the website online.
Its cause? To alter content scraping by way of LLMs which could use publicly available facts for AI-generated content without notifying or compensating the unique supply. This protocol places a little power back within the hands of website owners, allowing them to allow or disallow AI bots from content harvesting.
For example, placing Disallow: / in your llms.txt file instructs AI bots to avoid crawling your website totally.
2. How does llms.txt differ from robots.txt?
While each are crawler directives hosted in a website's root directory, they serve specific audiences:
| File | Purpose | Target |
|---|---|---|
| robots.txt | Manages access for search engine crawlers (e.g., Googlebot, Bingbot) | Traditional search engine optimization |
| llms.txt | Manages access for AI bots (e.g., GPTBot, ClaudeBot) | Large language model content sourcing |
The key difference among robots.txt and llms.txt is reason. While robots.txt is used to optimize indexing for SEO, llms.txt is targeted on AI records utilization governance, addressing growing concerns about how AI web crawlers extract and reuse records across the internet.
This new layout is a proactive response to ethical AI web scraping, ensuring content creators have a say in how their records contribute to the training of LLMs.
3. Why should one care about AI web crawlers gaining access to their website?
In these days's AI-driven content environment, AI bots don't just index---they examine. When an AI web crawler visits your web site, it is able to extract text, photos, and shape to educate big language models, occasionally without attribution or credit.
Here's why this matters:
- Loss of Control: Your carefully crafted weblog or particular product descriptions is probably utilized in AI responses without your know-how.
- Brand Dilution: Uncredited AI-generated content can mimic your tone and thoughts throughout the internet.
- Competitive Risk: Your proprietary facts can also circuitously assist competition using AI-generated content tools.
- Traffic Diversion: If AI summarizes your page without sending customers your way, you could see a drop in web traffic.
With rising concerns around records privateness for website content, implementing a llms.txt report permits for better AI bot visitors management and safeguards your digital assets.
4. Which AI groups are currently using llms.txt?
Several leading AI developers have stated the importance of moral content usage and have begun respecting llms.txt directives. Notable names consist of:
- OpenAI (GPTBot): Recognizes llms.txt and adheres to its disallow or permit guidelines.
- Anthropic (ClaudeBot): Also honors content regulations set through llms.txt.
- Google DeepMind (Gemini AI) and Meta are anticipated to put into effect or help comparable mechanisms soon.
These organizations are increasingly under scrutiny for large language version content sourcing, making the adoption of llms.txt an essential step in the direction of more obvious and respectful AI training practices.
For an up to date list of bots that help llms.txt, test their legitimate developer documentation or community monitoring platforms.
5. Can I block unique AI bots using llms.txt?
Yes, similar to with robots.txt, you may specify AI bots by name and trouble Allow or Disallow instructions as a consequence to your llms.txt file.
Here's a sample syntax:
makefile
User-Agent: GPTBot
Disallow: /
User-Agent: ClaudeBot
Disallow: /
User-Agent: *
Disallow: /
This lets in granular control over which AI bots can access your website and which are blocked completely. You can also use Allow: to provide restricted access to precise directories if needed.
This feature empowers website proprietors to have interaction in ethical AI content sharing on their own terms---deciding on whether or not to make a contribution to AI version development or keep their authentic content's integrity.
See What's Trending in Digital Marketing World
Do you want to know what are the latest developments in the digital world? Catch the detailed insights with our latest blogs.



